文本分类器构建方法及程序设计
19 Aug 2017自然语言处理(NLP)很基础的一块便是构建文本分类器,其应用领域也比较广泛,例如新闻题材、垃圾邮件的自动分类等。现阶段构建文本分类器的算法大致包括:朴素贝叶斯、SVM支持向量机、最大熵分类器和BP神经网络等。本文选取SVM算法对某银行客服录音数据进行分类,分类方法及程序设计如下:
注:在构建文本分类器之前,请先确定配备以下环境
Python 3.5及以上版本
jieba分词包
详情请见: python之结巴中文分词
· 数据预处理方法论
1.导入原始语料(存储格式:TXT,utf-8)
原始语料下载地址
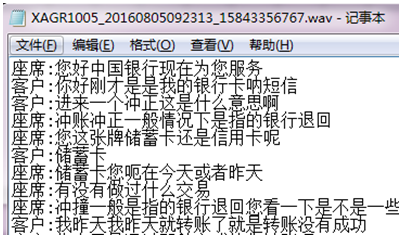
2.样本整理
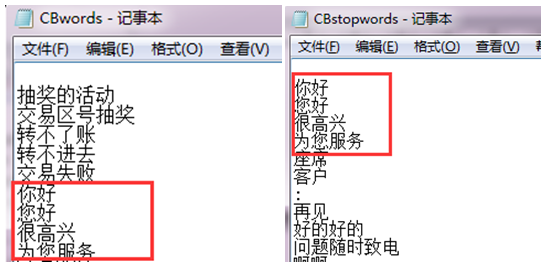
3.导入停用词库和自定义词库
停用词库和自定义词库下载地址
4.文本分词:
- 删除第1行和最后2行语句(规范话术)
- 去除停用词
- 添加自定义词典
- 结巴分词(精确模式)
清洗目的:
1)避免无意义词汇的出现,干扰后续TF-IDF词频提取的准确度
2)降低SVM支持向量机分类计算时的空间复杂度

· 数据预处理程序设计
import jieba
import jieba.analyse
#添加自定义词典
jieba.load_userdict('e:\\lexicon\\CBwords.txt')
# 创建停用词列表函数
def creadstoplist(stopwordspath):
stwlist = [line.strip() for line in open(stopwordspath, 'r', encoding='utf-8').readlines()]
return stwlist
# 对句子进行分词
def seg_sentence(sentence):
wordList = jieba.cut(sentence.strip())
stwlist = creadstoplist('e:\\lexicon\\CBstopwords.txt') #加载停用词路径
outstr = ''
for word in wordList:
if word not in stwlist:
if word != '\t':
outstr += word
outstr += " "
return outstr
#删除第1行和最后3行语句
infile = open('e:\\SVM预处理输入\\in1.txt', 'r', encoding='utf-8')
line_new = infile.readlines() #注意readline 和readlines
infile_new = ''.join(line_new[1:-3])
outfile_new = open("e:\\new.txt","w",encoding='utf-8')
outfile_new.write(infile_new)
infile.close()
outfile_new.close()
#结果输出到txt文件夹中
infile_new1 = open("e:\\new.txt","r",encoding='utf-8')
outfile = open('e:\\SVM预处理输出\\outfile1.txt', 'w', encoding='utf-8')
for line in infile_new1:
line_seg = seg_sentence(line)
outfile.write(line_seg+'\n')
infile_new1.close()
outfile.close()
import jieba
import jieba.analyse
#添加自定义词典
jieba.load_userdict('e:\\lexicon\\CBwords.txt')
# 创建停用词列表函数
def creadstoplist(stopwordspath):
stwlist = [line.strip() for line in open(stopwordspath, 'r', encoding='utf-8').readlines()]
return stwlist
# 对句子进行分词
def seg_sentence(sentence):
wordList = jieba.cut(sentence.strip())
stwlist = creadstoplist('e:\\lexicon\\CBstopwords.txt') #加载停用词路径
outstr = ''
for word in wordList:
if word not in stwlist:
if word != '\t':
outstr += word
outstr += " "
return outstr
#删除第1行和最后3行语句
infile = open('e:\\SVM预处理输入\\in1.txt', 'r', encoding='utf-8')
line_new = infile.readlines() #注意readline 和readlines
infile_new = ''.join(line_new[1:-3])
outfile_new = open("e:\\new.txt","w",encoding='utf-8')
outfile_new.write(infile_new)
infile.close()
outfile_new.close()
#结果输出到txt文件夹中
infile_new1 = open("e:\\new.txt","r",encoding='utf-8')
outfile = open('e:\\SVM预处理输出\\outfile1.txt', 'w', encoding='utf-8')
for line in infile_new1:
line_seg = seg_sentence(line)
outfile.write(line_seg+'\n')
infile_new1.close()
outfile.close()
· SVM自动分类器方法论
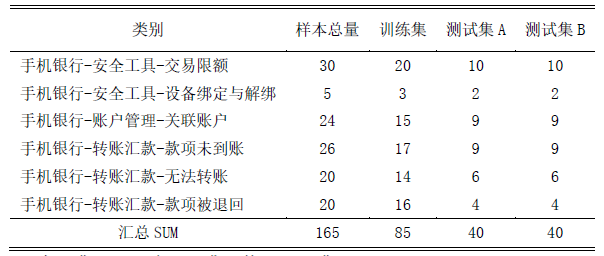
1.导入数据集(存储格式:CSV)
预处理后数据集下载地址

Num表示id号(随意编排)
Content表示数据预处理后文本内容
Lable表示文本内容所对应的分类标签
2.划分为训练集和测试集A
3.转化为词频向量化矩阵,并计算TF-IDF值
4.训练SVM文本分类器
5.测试分类结果
6.计算精确度
7.稳健性检验
检验目的:提高文本分类器可信度
检验方法分别为以下两种:
1)训练集不变,将测试集A替换成测试集B,由此预测测试集B的分类结果
2)训练集与测试集A进行同类别相互替换,由此重新训练并预测分类器结果
8.整理预测结果

label 人工分类标签
predict 分类器预测标签
· SVM自动分类器程序设计
import csv
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline
from sklearn import metrics
from sklearn.grid_search import GridSearchCV
# 1.读取训练集
def readtrain():
with open('e:\\test1.csv', 'r') as csvfile:
reader = csv.reader(csvfile)
column1 = [row for row in reader]
content_train = [i[1] for i in column1[1:]] #第一列为文本内容,并去除列名
opinion_train = [i[2] for i in column1[1:]] #第二列为分类标签,并去除列名
print ('数据集共有 %s 条句子' % len(content_train))
train = [content_train, opinion_train]
return train
def changeListCode(b):
a = []
for i in b:
a.append(i.decode('utf8'))
return a
train = readtrain() #读取readtrain数据集
content = train[0] #第一行文本内容赋给content
opinion = train[1] #第二行分类标签赋给opinion
# 2.划分训练集与测试集
train_content = content[:85] #训练集文本内容
test_content = content[85:] #测试集文本内容
train_opinion = opinion[:85] #训练集分类标签
test_opinion = opinion[85:] #测试集分类标签(用于计算精确度)
# 3.文本向量化
vectorizer = CountVectorizer() #将向量化函数赋给vectorizer
tfidftransformer = TfidfTransformer()
tfidf = tfidftransformer.fit_transform(vectorizer.fit_transform(train_content)) # 先转换成词频矩阵,再计算TFIDF值
print (tfidf.shape)
# 4.训练文本分类器
text_clf = Pipeline([('vect', CountVectorizer()), ('tfidf', TfidfTransformer()), ('clf', SVC(C=0.99, kernel = 'linear'))])
text_clf = text_clf.fit(train_content, train_opinion)
# 5.预测文本分类结果
predicted = text_clf.predict(test_content)
print ("打印预测结果:")
print (predicted) #打印预测分类结果
# 6.计算精确度
print ("============================================")
print ("计算预测结果精确度")
print ('SVC',np.mean(predicted == test_opinion))
· SVM自动分类器预测结果
打印预测结果:
['手机银行-安全工具-交易限额' '手机银行-安全工具-交易限额' '手机银行-安全工具-交易限额' '手机银行-安全工具-交易限额'
'手机银行-安全工具-交易限额' '手机银行-安全工具-交易限额' '手机银行-安全工具-交易限额' '手机银行-安全工具-交易限额'
'手机银行-安全工具-交易限额' '手机银行-安全工具-交易限额' '手机银行-安全工具-设备绑定与解绑' '手机银行-转账汇款-无法转账'
'手机银行-账户管理-关联账户' '手机银行-账户管理-关联账户' '手机银行-账户管理-关联账户' '手机银行-账户管理-关联账户'
'手机银行-账户管理-关联账户' '手机银行-账户管理-关联账户' '手机银行-账户管理-关联账户' '手机银行-账户管理-关联账户'
'手机银行-账户管理-关联账户' '手机银行-转账汇款-款项未到账' '手机银行-转账汇款-款项未到账' '手机银行-转账汇款-款项未到账'
'手机银行-转账汇款-款项未到账' '手机银行-转账汇款-款项未到账' '手机银行-转账汇款-无法转账' '手机银行-转账汇款-款项未到账'
'手机银行-转账汇款-款项未到账' '手机银行-转账汇款-款项未到账' '手机银行-转账汇款-款项未到账' '手机银行-转账汇款-无法转账'
'手机银行-转账汇款-无法转账' '手机银行-转账汇款-无法转账' '手机银行-转账汇款-无法转账' '手机银行-转账汇款-无法转账'
'手机银行-转账汇款-款项被退回' '手机银行-转账汇款-款项未到账' '手机银行-转账汇款-款项被退回' '手机银行-转账汇款-款项被退回']
============================================
计算预测结果精确度
SVC 0.9
分类: 自然语言处理