相似词:用gensim实现word2vec和fasttext
20 Nov 2019最近在看2019斯坦福NLP公开课,突然萌生一个想法,准备把课程所有涉及到的知识点,都用python实现一遍。由于第一课讲到word2vec,遂写下用gensim实现word2vec和fasttext的方法。其实gensim库官方文档已经介绍的很详细,想追根溯源的同学可参考gensim官方文档,本博文只记录具体的实现路径。
1.导入python所需要的包
from gensim.models import fasttext
from gensim.models import word2vec
import pandas as pd
import logging
import jieba
其中gensim和jieba需要单独安装,使用anaconda的同学可以参考Anaconda安装其他第三方库
2.数据导入与预处理
data = pd.read_csv("d:\\test.csv",sep="\t",encoding='gbk',header=None)
sentance = list(data[0])
# 对每行句子进行中文分词
def segment_sen(sen):
sen_list = []
try:
# 可以考虑添加业务词库、去停用词,具体参考jieba官方文档
sen_list = jieba.lcut(sen)
except:
pass
return sen_list
# 将数据变成gensim中,word2wec函数的数据格式
sens_list = [segment_sen(i) for i in sentance]
3.训练word2vec模型
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
model = word2vec.Word2Vec(sens_list,min_count=1,iter=20)
model.save("word2vec.model")
4.调用word2vec模型
model.wv.most_similar("手续费")

5.fasttext模型训练及调用
word2vec和fasttext算法最大的差异在,前者无法识别模型中未训练过的词,而后者可以解决未登录词的问题。
# 训练fasttext模型
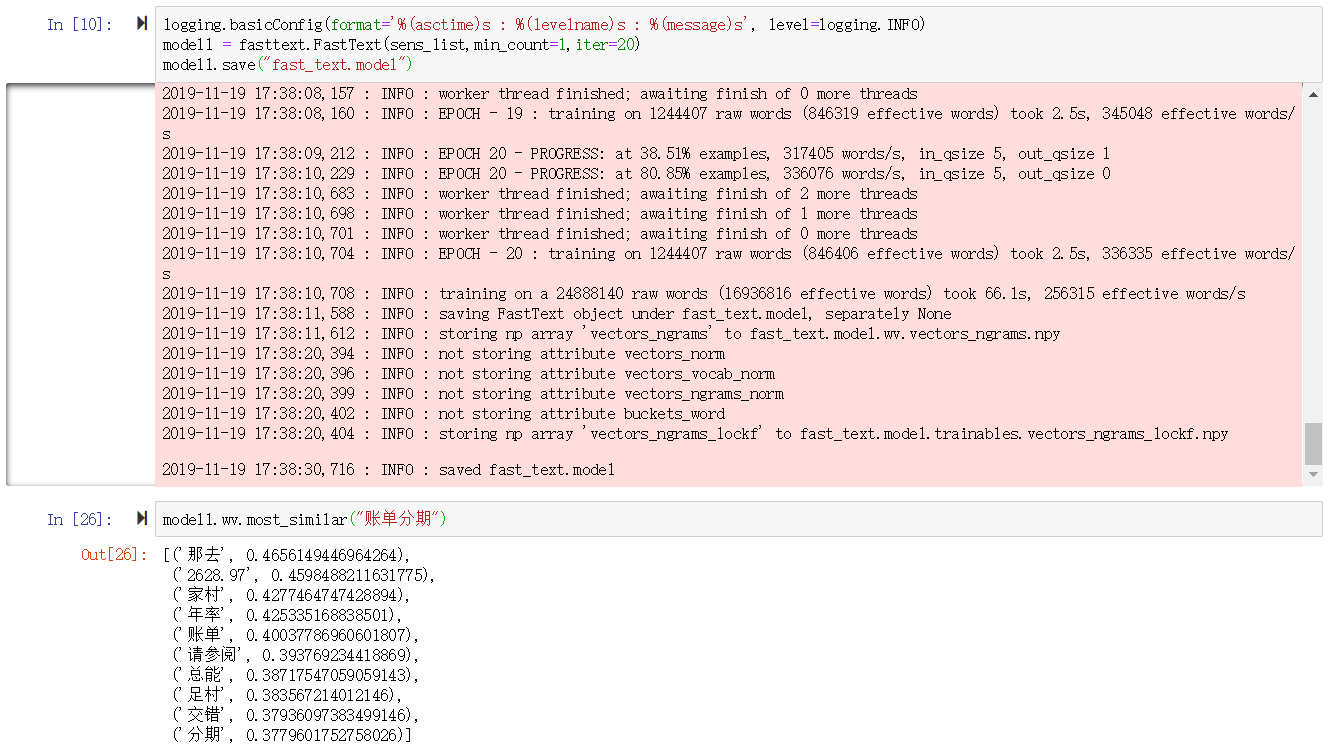
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
model1 = fasttext.FastText(sens_list,min_count=1,iter=20)
model1.save("fast_text.model")
# 调用fasttext模型
model1.wv.most_similar("账单分期")
附1.Gensim模型参数及再训练
# Gensim模型参数调整
model = gensim.models.Word2Vec(sentences, #输入语料
window=2, #窗口大小
size=100, #维度
alpha=0.03, #学习率
negative=20, #负采样数量
min_count=2, #最小出现次数
workers=10) #进程数量
# Gensim模型再训练
new_model = gensim.models.Word2Vec.load('mymodel')
new_model.train(more_sentences)
附2.模型调优思路
1.保证训练数据集的量足够大,且文本中没有过多错误的词汇,例如手续费被翻译成水费;
2.数据预处理分词阶段,需要整理好对应的业务词库和停用词库;
3.若没有大量数据或高性能GUP去构建模型,可考虑已训练好的词向量模型,例如腾讯词向量模型;
分类: 自然语言处理