机器学习之聚类评估指标(轮廓系数)
28 Apr 2018最近在整理聚类算法的时候偶然发现一个指标——轮廓系数,仔细研究之后发现是一个易于理解的用来评估聚类效果好坏的指标,因此在这里和大家分享一样。轮廓系数的值介于[-1,1]之间,越趋于1代表聚类效果越好,具体计算方法如下:
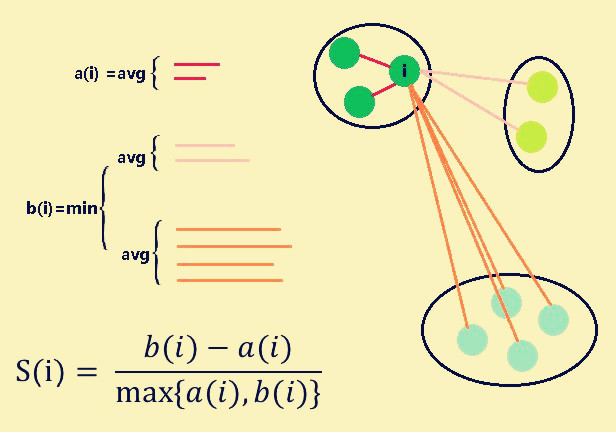
1. 计算样本i到同簇其他所有样本的平均距离,记为a(i)。a(i)越接近0则表示样本i聚类效果越好。
2. 计算样本i到其他每个簇中所有样本的平均距离,选取平均距离最小的值记为b(i)。b(i)越大则表示样本i聚类效果越好。
3. 计算b(i)与a(i)的极差,除以max{a(i),b(i)},这时就会出现以下3种场景:
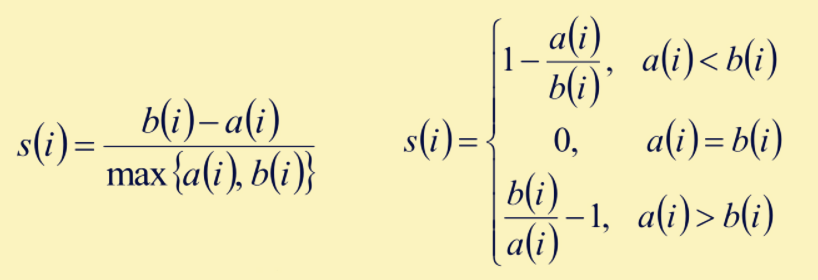
4. 判别结果:
若s(i)接近1,则说明样本i聚类合理;
若s(i)接近-1,则样本i更应该分类到另外的簇;
若s(i)接近0,则说明样本i在两个簇的边界上;
注意:轮廓系数相关程序已在Python之 文本聚类中给出,大家可自行研究。
分类: 机器学习算法