还在担心关键词识别率的问题么?
15 Nov 2019清晨起床说一句“打开窗帘”,煦暖阳光撒进卧室,走进厨房说一句“来杯美式咖啡,无糖加奶”,咖啡机启动工作,咖啡香味充满整个房间,端起咖啡走入客厅,说一句“来点轻音乐吧”,柔和的音乐开始在房间内飘荡。多么美好的智能化生活图景!然而实际很可能是窗帘虽然打开了,但咖啡里没有牛奶,音响播放的是嘈杂的爵士乐,而非柔和的轻音乐。这都是因为机器在识别自然语言时,常常会“听岔”、“听不懂”,因此也就无法指挥咖啡机、音响完成正确的指令。

机器理解人的自然语言,要靠“听见”+“听懂”两个步骤,也就是语音识别和语义理解两个环节。这两个环节会互相制约,从而影响交互效果。和人理解对话类似,机器想要理解一句话也并不需要弄清楚句中每一个词语和它们的排列组合,而是靠关键词获得主要的信息量。例如“今天天气真的太舒服了”,机器提取到“今天”、“天气”、“舒服”三个关键词,就可以基本准确理解用户谈论的话题。那么假设语音翻译的过程中将原句翻译成“今天天气真的太束缚了”,机器该如何理解这句话?所以说,关键词的准确识别在自然语言处理的过程中具有至关重要的意义。
在语音转译的过程中,关键词转译错误的问题主要集中在少量不常用的词汇上:不同领域专业术语,不同企业之间产品、业务名称等等。这种情况下,直接面向语音识别引擎,通过大量语音标注训练语言模型从而优化关键词识别率的方式,在实际工程应用中存在周期长、成本高的问题,难以适应复杂多变的业务需求,我们需要一套实时性更高、针对性更强、操作更便利的关键词优化方法。基于这样的考虑,智汇文本分析平台以优化不同应用环境中的意图识别效果为目的,推出了不依赖于语音引擎的关键词文本纠错技术,以下简称文本纠错。
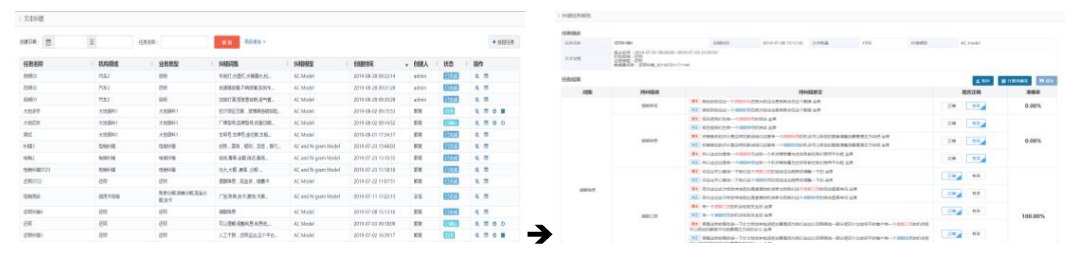
用户使用文本纠错功能,只需要准备一批原始场景文本(如语音识别结果)和指定关键词即可,系统会自动从大量文本中找出可能出现的转译错误的内容,并根据人工校验结果对后续导入的文本进行自动的文本纠错。经过长期、大量、持续的反馈训练,文本纠错功能能够持续不断的帮助企业提升文本数据的关键词识别率,从而优化企业的数据资产价值。现基于关键词的文本纠错技术已集成到中金智汇的各类应用型产品中,并为金融、保险、电商等多个行业客户提供价值。
分类: 相关资讯