Python之 关键词提取
21 Apr 2018 最近受邀去帮广发银行的高层培训NLP相关知识,既定的任务是教会他们如何用Python实现自然语言处理。想着既然要备课,就顺带着将NLP相关的知识梳理一下,放到博客中。
自然语言处理说简单些就是程序员将自然语言(英语、汉语等)编译为程序语言(Python、Java等)最后让机器解析成汇编语言的过程。那么就自然语言本身来看,其中就包括单个词、短语、句子、段落和篇章,不同的切词、提词的方法都会影响到后续句子级以上的处理,而不同句子、段落、篇章的算法也会各有优势和劣势,这里分别列举一些常用算法以帮助期望快速了解NLP的朋友。

关键词提取这里主要列举两种常用的计算方法TF-IDF和TextRank,TF-IDF表示在本文档中经常出现,且在其他文档中很少出现的词,TextRank则是基于图排序的算法(根据投票原理,让每个单词给它相邻的词投赞成票,票的权重取决于词自身的票数)。
Python关键词提取(TF-IDF)程序如下:
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
if __name__ == "__main__":
corpus=["鲜花 多少钱",#第一类文本切词后的结果,词之间以空格隔开
"白百合 多少钱",#第二类文本的切词结果
"水仙花 多少钱",#第三类文本的切词结果
"水果 多少钱"]#第四类文本的切词结果
vectorizer=CountVectorizer()#该类会将文本中的词语转换为词频矩阵,矩阵元素a[i][j] 表示j词在i类文本下的词频
transformer=TfidfTransformer()#该类会统计每个词语的tf-idf权值
tfidf=transformer.fit_transform(vectorizer.fit_transform(corpus))#第一个fit_transform是计算tf-idf,第二个fit_transform是将文本转为词频矩阵
word=vectorizer.get_feature_names()#获取词袋模型中的所有词语
weight=tfidf.toarray()#将tf-idf矩阵抽取出来,元素a[i][j]表示j词在i类文本中的tf-idf权重
for i in range(len(weight)):#打印每类文本的tf-idf词语权重,第一个for遍历所有文本,第二个for便利某一类文本下的词语权重
print ("-------这里输出第",i,u"类文本的词语tf-idf权重------")
for j in range(len(word)):
print (word[j],weight[i][j])
Python关键词提取(TF-IDF)结果如下:
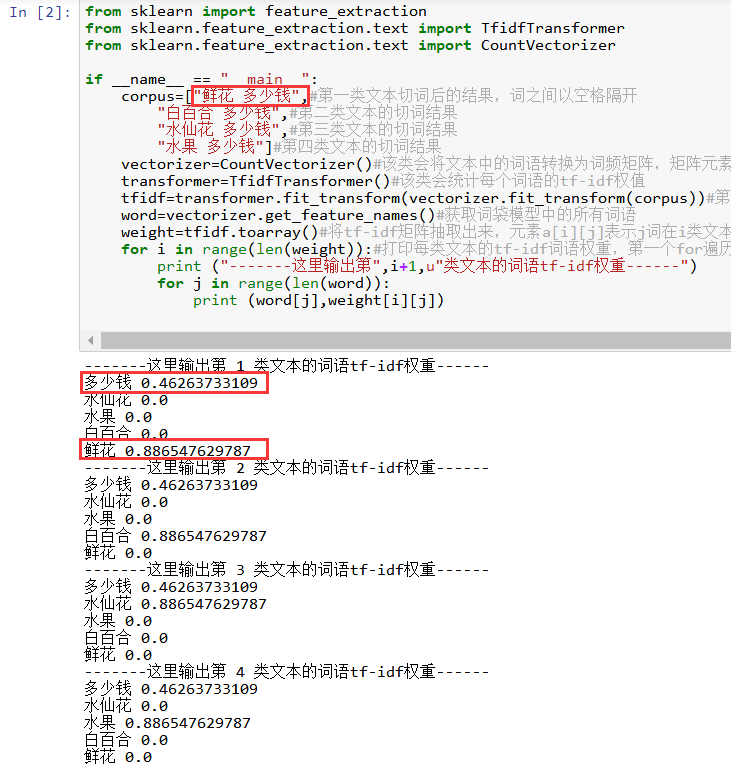
从结果中可以看出,程序没有问题,但深究文本会发现,我希望提取的关键词是“多少钱”而并非商品名称,因此面对这类文本时TF-IDF算法失效,这时我们可以采用TextRank提取关键词。
from textrank4zh import TextRank4Keyword
text = "鲜花 多少钱 白百合 多少钱 水仙花 多少钱 水果 多少钱"
word = TextRank4Keyword()
word.analyze(text,window = 2,lower = True)
w_list = word.get_keywords(num = 20,word_min_len = 1)
print ('关键词:')
for w in w_list:
print(w.word,w.weight)
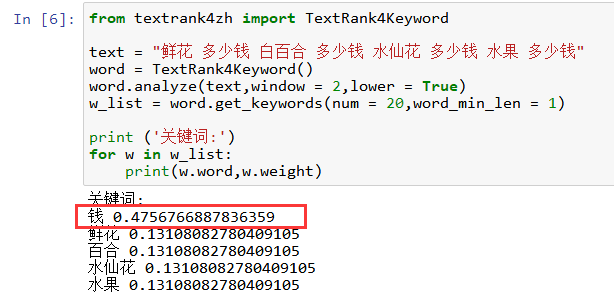
Python关键词提取(TextRank)结果如下:
分类: 自然语言处理