Python机器学习之因子分析
24 May 2018 最近分析客户偏好的时候用到了因子分析,感觉是NLP与机器学习一个不错的结合点,遂在此记录一下。
因子分析的主要目的就是为了降维,意思是将多个字段的值按照不同的权重合为一个字段,其前提条件是需要合并的几个字段具有相关性,百度上有很多关于因子分析的计算公式,大家可以自行搜索一下,本文只给出因子分析的python计算程序。
这是借助因子分子做的客户偏好雷达图:
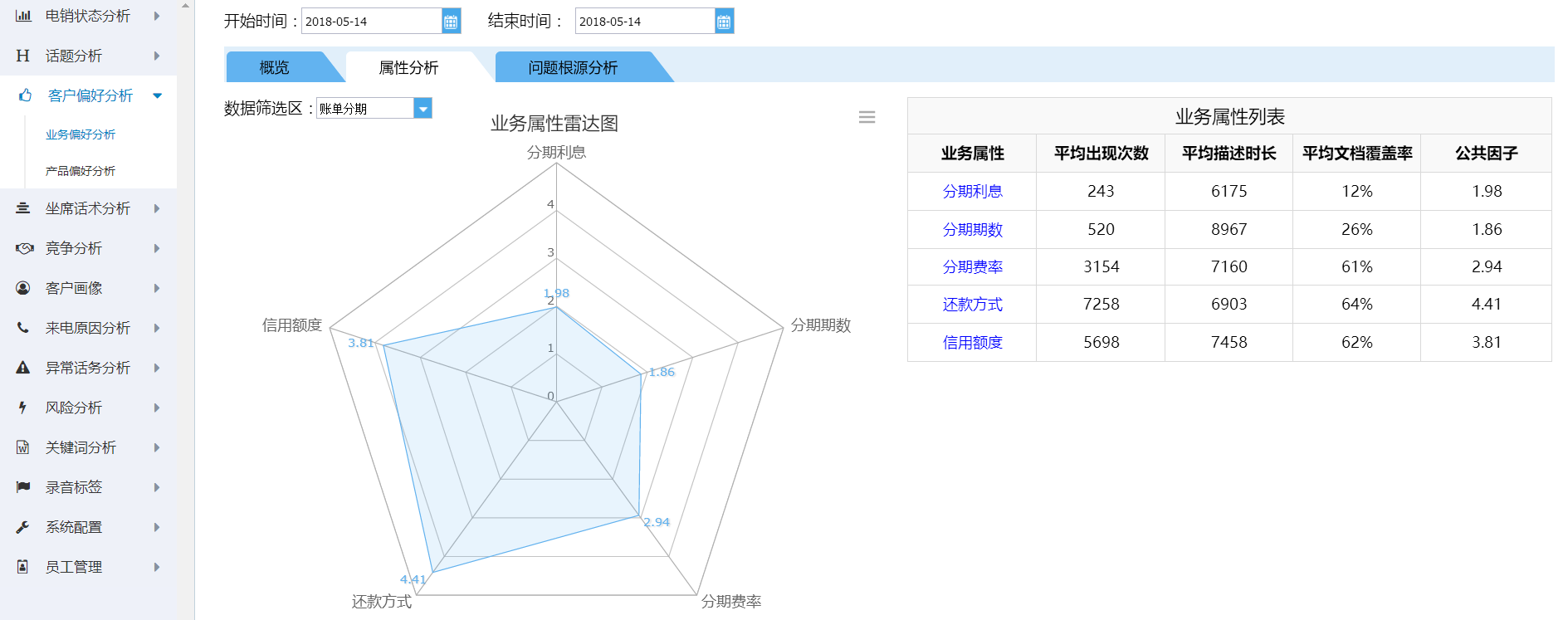
原始数据集下载地址:yinzifenxi.csv
· 因子分析python程序
import csv
import numpy as np
from sklearn.decomposition import FactorAnalysis
# ==== 读取原始数据集 ====
with open("d:\\yinzifenxi.csv","r") as f: # 读取原始CSV文件路径
data1 = np.loadtxt(f,delimiter=",",skiprows=1)
f = open("d:\\yinzifenxi.csv","r")
rows_dict = csv.DictReader(f)
# print(data1) # 打印原文件数据
# ==== 创建空白的CSV文件 ====
fieldnames = ['frequency','avg','coverage','yinzifenxi']
f1 = open("d:\\yinzifenxi1.csv","w",newline='') # 创建一个空白新的CSV文件
writer = csv.DictWriter(f1,fieldnames=fieldnames)
# ==== 因子分析 ====
data = np.array(data1[1:], dtype = np.float64) # 从第二行开始
fa = FactorAnalysis(n_components = 1) # 因子分析参数设置 1表示一维
fa.fit(data) # 因子分子数据输入
tran_data = fa.transform(data)
tran_data1=tran_data[:,0]
# print (tran_data1) # 打印因子分析结果
# ==== 将结果输入到CSV文件 ====
writer.writeheader()
for i,row in enumerate(rows_dict): # 将结果写入CSV
row['yinzifenxi'] = tran_data1[i-1]
writer.writerow(row)
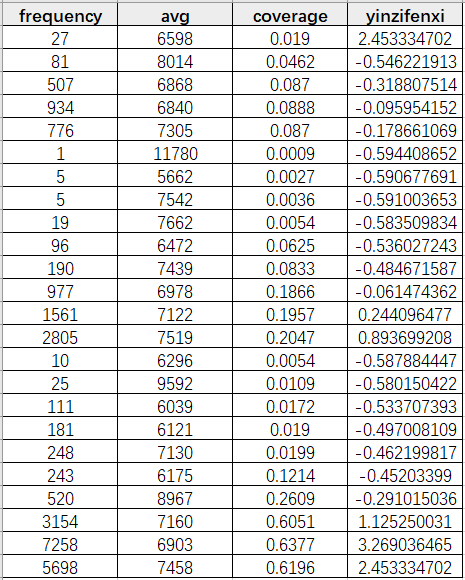
· 因子分析结果
分类: 机器学习算法