基于图的机器学习技术
15 Sep 2017 近年来,机器学习技术的突飞猛进促使计算机系统能够解决现实世界中诸多复杂的问题。其中之一便是Google发布大规模的、基于图的机器学习平台,而这套技术正是我们日常使用的收件箱提醒、Allo智能信息回复、Google Photos图像识别等功能背后的技术工具之一。
相对于需要经过大规模带标签的数据训练,才能够展现出其预测能力的“有监督”的机器学习方法,基于图的机器学习技术受到人类在已有知识(有标签数据)和全新未知结果(无标签数据)之间搭建学习桥梁的启发,使用称之为“半监督”学习的方法,使系统能够在稀疏数据集上进行训练,从而能够避免“有监督”学习中,对于每个新的任务都需要耗费大量的时间和精力去采集标签数据的问题。此外,基于图的半监督学习方法使得系统在学习的时候能够同时吸收带标签和不带标签的数据,这样有助于改善数据的底层结构,混合多种不同信号的特征,例如带有原始特征的知识图谱相关信息等。

基于图的机器学习算法核心就是构建图本身,由此我们需要定义节点、边、以及每条边的权重。在整个学习过程中,最主要的问题就是如何生成图以及连接方式的选择。图有各种各样的大小和形状,并且能够与多种不同的来源进行结合,Google所发布的基于图的机器学习平台正是抓住了这一痛点,能够直接从推断或已知的数据要素间关系中自动地生产图。为了更好的理解基于图的机器学习系统是如何运转的,本文列举以下的示例:
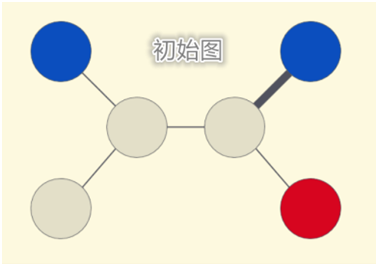
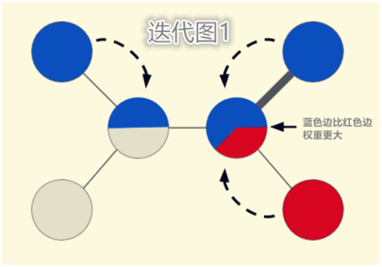
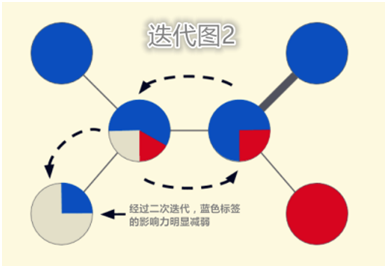
如图所示,灰色节点代表无标签数据,彩色节点代表有标签数据,节点数据之间的关系通过边表示,边的粗细程度代表边的权重,由此我们需要解决的问题是预测图表中每一个节点的颜色。基于图的机器学习技术最简单的实现原理,就是学习图像中每一个节点的颜色标签,相邻标签则依据相互之间链接的强度来分配与之相似的颜色。一个较为简洁的方法就是尝试一次性全部学完标签分配,但这种方法并不能拓展到大型的图上。另一个方法就是通过把标签节点的颜色传递给相邻节点,然后重复这一过程,从而不断的获得优化。通过第二种方法,我们可以升级每一个节点的标签,重复操作,直到整个图都是彩色的,而这一过程在优化相似的难题上也被证明是极其有效的。
现今,基于图的机器学习技术被应用到越来越多的领域中,例如自然语言处理中的情绪标记,金融领域中的反欺诈模型构建,当然还包括一些智能提醒、对话理解等应用。相信随着基于图的机器学习技术不断发展,在不久的将来,互联网规模膨胀的问题也将获得圆满的解决。
分类: 相关资讯